作者:赵颖
AI大战,究竟谁才是最终赢家?
或许既不是人们讨论最激烈的OpenAI,也不是微软、谷歌等科技巨头,开源AI可能将在未来占领高地。
周四,据媒体semianalysis报道,谷歌研究员在一份泄密文件中坦言,谷歌没有护城河,OpenAI也是如此,与开源AI竞争将难以占据优势。
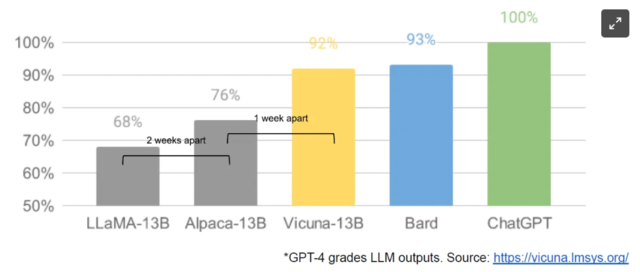
正如文件中提到的,开源模型训练速度更快,可定制性更强,更私密,而且比同类产品能力更出色。他们正在用100美元和130亿的参数做一些“谷歌1000万美元和540亿的参数难以企及”的事情,而且在短短几周内就能做到,而不是几个月。
对于用户而言,如果有一个没有使用限制、免费、高质量的替代品,谁还会为谷歌的产品付费呢?
以下是谷歌泄密文件:
谷歌没有护城河,OpenAI也是如此
我们对OpenAI进行了很多审视和思考,谁会跨越下一个里程碑?下一步会有什么行动?
但令人不安的事实是,我们没有能力赢得这场军备竞赛,OpenAI也是如此。在我们争吵不休的时候,第三个派别一直在悄悄地抢我们的饭碗。
我指的是开源AI,简而言之他们正在抢走我们的市场份额。我们认为的“主要的开放问题”如今被解决了,并且已经触达用户。仅举几例:
手机上的LLMs:人们以5 tokens/sec在Pixel 6上运行基础模型。
可扩展的个人人工智能:你可以在一个晚上用你的笔记本电脑上微调生成个性化的AI助手。
负责任的发布:这个问题并没有“解决”,而是“避免”。有的整个网站充满了没有任何限制的艺术模型,而文字也不甘落后。
多模态性:目前的多模态ScienceQA SOTA是在一小时内训练完成的。
虽然我们的模型在质量上仍有一点优势,但差距正在以令人惊讶的速度迅速缩小。开源模型训练速度更快,可定制性更强,更私密,而且比同类产品能力更出色。他们正在用100美元和130亿的参数做一些“谷歌用1000万美元和540亿的参数难以企及”的事情,而且在几周内就能做到,而不是几个月。这对我们有深远的影响:
我们没有诀窍。我们最大的希望是向谷歌以外的其他人学习并与他们合作。我们应该优先考虑实现3P整合。
当免费的、不受限制的替代品质量相当时,人们不会为一个受限制的模式付费。我们应该考虑我们的附加值到底在哪里?
大模型正在拖累我们,从长远来看,最好的模型是那些可以快速迭代的模型。
发生了什么?
三月初,Meta的大语言模型LLaMA被泄露,开源社区得到了第一个真正有能力的基础模型。它没有指令或对话调整,也没有RLHF。尽管如此,社区立即理解了他们所得到的东西的意义。
随后,巨大的创新成果接连涌现出来,发展仅仅间隔了几天。现在,不到一个月的时间,就出现了指令调整、量化、质量改进、人类评价、多模态、RLHF等变体,许多都是相互关联的。
最重要的是,他们已经解决了缩放(scaling)问题,达到了任何人都可以调整的程度。许多新的想法都来自于普通人,门槛已经从一个主要研究机构下降到一个人、一个晚上和一台强大的笔记本电脑。
在许多方面,这对任何人来说都不那么惊讶。当前开源大模型的复兴紧随生成图像模型的火热,开源社区并没有忘记这些相似之处,许多人称这是LLMs的“Stable Diffusion”时刻。
通过低秩矩阵微调方法(LoRA),结合规模上的重大突破(如大模型Chinchilla),公众可以用较低成本参与进来;在这两种情况下,获得一个足够高质量的模型可以引发了世界各地的个人和机构的想法和迭代的热潮,很快就会超越大型企业。
这些贡献在图像生成领域非常关键,使Stable Diffusion公司走上了与Dall-E不同的道路。拥有一个开放的模式带来的产品整合、市场、用户界面和创新,这些都是Dall-E所没有的。
其效果是可想而知的:在文化影响方面,与OpenAI的解决方案相比,它迅速占据了主导地位,变得越来越相互依赖。同样的事情是否会发生在LLM上还有待观察,但广泛的结构元素是相同的。
我们错过了什么?
开源最近成功的创新直接解决了我们仍在挣扎的问题,多关注他们的工作可以帮助我们避免重蹈覆辙。
LoRA是一个非常强大的技术,我们应该多加注意,LoRA的工作原理是将模型更新表示为低秩因子化,这将更新矩阵的大小减少了几千倍。这使得模型的微调只需要一小部分的成本和时间。能够在几个小时内在消费类硬件上对语言模型进行个性化调整是一件大事,特别是对于那些涉及在近乎实时的情况下纳入新的和多样化的知识。这项技术的存在在谷歌内部没有得到充分的利用,尽管它直接影响了我们一些最雄心勃勃的项目。
从头开始重新训练模型是一条艰难的道路,LoRA之所以如此有效,部分原因在于--像其他形式的微调--是可堆叠的,像指令调整这样的改进可以被应用,然后随着其他贡献者增加对话、推理或工具使用而被利用。虽然单个的微调是低等级的,但它们的总和不需要,允许模型的全等级更新随着时间的推移而积累。
这意味着,随着新的和更好的数据集和任务的出现,模型可以以较低成本保持更新,而不需要支付全面训练的费用。
相比之下,从头开始训练大模型,不仅丢掉了预训练,还丢掉了之前的任何迭代改进。在开源的世界里,这些改进在不久之后就会占据主导地位,从而使全面重新训练的成本变得非常昂贵。
我们应该深思熟虑,每个新的应用或想法是否真的需要一个全新的模型。如果我们真的有重大的架构改进,那么我们应该投资于更积极的提炼形式,尽可能地保留前一代的能力。如果我们能在小模型上更快地进行迭代,那么从长远来看,大模型并不是更有优势。
LoRA更新的成本非常低(约100美元),这意味着几乎任何有想法的人都可以生成。训练时间少于一天是很正常的,在这种速度下,所有这些微调的累积效应不需要很长时间就可以克服初始的模型规模劣势。
数据质量的扩展性比大小更好体现在这些项目中,许多模型通过在小型、高质量的数据集上进行训练来节省时间。这表明在数据扩展规律有一定的灵活性,同时正迅速成为谷歌之外的标准训练方式。这两种方法在谷歌都不占优势,但幸运的是,这些高质量的数据集是开源的,可以免费使用。
与开源直接竞争是一个赔本生意
最近的这一进展对我们的商业战略有直接、重大的影响,如果有一个没有使用限制、免费、高质量的替代品,谁还会为谷歌的产品付费呢?
而且,我们不应该指望能够追赶上,现代互联网在开放源码上运行是有原因的,开放源码有一些无法复制的优势。
我们更需要他们,对我们的技术进行保密始终是不稳固的,谷歌的研究人员经常变动,所以我们可以假设他们知道我们所知道的一切,而且只要这个途径是开放的,相关技术就会继续散播出去。
但在技术方面保持竞争优势变得更加困难,世界各地的研究机构都在彼此的工作基础上,以广度优先的方式探索解决方案的空间,远远超过了我们的能力。我们可以尝试紧紧抓住我们的秘密,而外部的创新会稀释它们的价值,或者我们可以尝试相互学习。
本文地址: https://www.xiguacaijing.com/news/xingye/2023/47323.html



















赞助商